Published
- 42 min read
[読書録]入門 監視
![img of [読書録]入門 監視](/_astro/2024-01-20-1.CZqda1V0_ZfyA78.jpg)
読んだ本
入門 監視(2019/1/17発売, 228ページ)
感想サマリ
監視とは、あるシステムやそのシステムのコンポーネントの振る舞いや出力をチェックし続ける行為である
本書では監視という用語をこのように定義し、監視のあり方をなぜ監視が必要なのかという観点からどのようにシステムの監視を行えばよいかまで紹介している。
IT企業でシステム運用を行っている人なら、誰しもシステム監視という業務を行っていると思うが、本書はその監視業務について体系的にまとめられた本である。
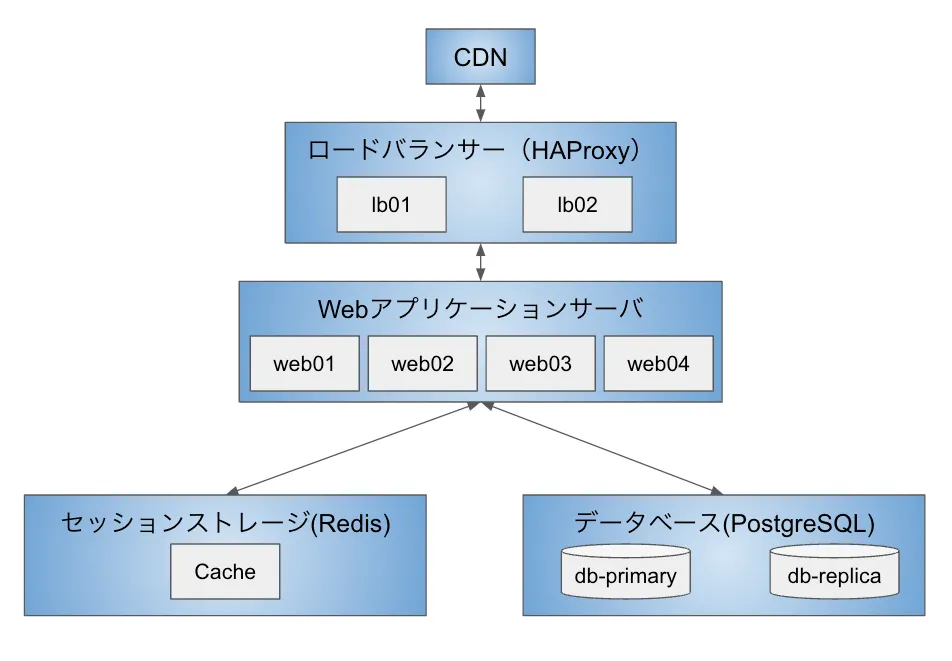 本書p.167 図11-1 仮想サービスTater.lyのアーキテクチャ図から筆者が抜粋
本書p.167 図11-1 仮想サービスTater.lyのアーキテクチャ図から筆者が抜粋
11章の仮想システムで、このようなアーキテクチャが想定されており、どのような監視を行うべきかを最後に掲載されている。
本書の5章あたりを読めば、このアーキテクチャでログやアラートの設定だけではなく、ビジネスKPIの設定までが重要だということがわかり、不測の事態であるアラートを受けるオンコール体制やインシデント管理についても紹介されている。
紹介されているツール類はパブリッククラウドをしっかり活用していると、少し応用しづらい内容もあるが、監視業務全般を体系的に学ぶことができるので、監視業務に携わっている人は必読の書にはなると感じた。
また、本書の付録として、はてなのMackerelプロダクトマネージャーである松木(songmu)さんの章が設けられており、その中でObservabilityが新しいパラダイムであることも触れられていた。
本書が出版されたのは2019年だが、そのあたりから話題になりだしているオブザーバビリティの考えにも展開していく動きが見えるのが監視領域の技術進化を感じられて面白かった。
本書の関連リンク
- 書評「入門 監視」雰囲気で監視をやっているすべての人にオススメ(DevelopersIO)
- 【書評&要約】「入門 監視」の全章をまとめてみる(顧客フロントSEのIT勉強ブログ)
- 「入門 監視」を読んだので要約する(Qiita)
内容メモ
はじめに
-
監視とは、あるシステムやそのシステムのコンポーネントの振る舞いや出力をチェックし続ける行為である
-
これからお話しする基本原則は、時代を超えるものです
1章 監視のアンチパターン
-
アンチパターンとは、一見よいアイディアだが実装するとて手痛いしっぺ返しを食らうものをいう
5つのアンチパターン
- ツール依存
-
ツール駆動なチームは、ミッション駆動なチームより効率的になることはない
-
全部やってくれるツールが欲しいというのは、妄想でしかありません
- プロのメカニックが工具箱を持ち歩くように、汎用化あるいは専門家されたツールが必要
- 監視する行為が監視対象を変化させてしまう観察者効果は気にしないでよい
- エージェントのインストールおよび管理を気にするのであれば、構成管理ツールを使うべき
- ツールの勝手な採用を避けるため、会社内でツールに関する規格を作りたい場合は、人(チームのマネージャー、会計部門など)と話す
- カーゴ・カルト・サイエンス - 戦争中郡容器が物資を運んで着陸するのをみてきた連中は、滑走路らしきものを造り、その両側に火をおいたりしながら、飛行機が来るのを待っているようなコラム
- 形の上ではちゃんと整っているようだが、全然その効果はなく、期待する飛行機がいつまでもやってこないエピソード
-
知名度の高い会社が使っているというだけで採用してはいけません
-
監視とは複雑な問題の塊であると考えると、すべてを1つのツールあるいはダッシュボードシステムに詰め込もうとするのは、効率的に仕事をしようとするのを妨げてしまうことになります
-
- 役割としての監視
-
監視とは役割ではなくスキルであり、チーム内の全員がある程度のレベルに至っておくべき
- 専門家ごとに監視する体制を作るのはアンチパターン
-
セルフサービスの監視ツールを作ったり提供したりする責任を持つチームや人を作ることは問題ありませんが、1人の肩に監視の全責任を押し付けてしまうような会社になることはアンチパターン
-
- チェックボックス監視
-
チェックボックス監視とは、「これを監視してます」と言うための監視システムのこと
- 組織の中で上位に位置する人や、コンプライアンス法令の遵守が求められるようなケース
- アンチパターンを直す方法
- 「動いている」かどうかを監視する
- アラートに関しては、OSのメトリクスはあまり意味がない
- メトリクスをもっと高頻度で取得する
-
- 監視を支えにする
-
注意を要するサービスを運用していて、そこに監視をどんどん追加している状態なのに気づいたら、そういったことはやめてサービス自体を安定して回復力のあるものにすることに時間を使いましょう
-
- 手動設定
- クラウドベースのアーキテクチャを監視するのは、従来型のアーキテクチャを監視するのと比べて、個別のなにかを監視するのではなく、何かの集合全体を監視することになる
- 監視設定は100%自動化すべき。各サービスは誰かが設定を追加するのではなく、勝手に登録されるようにする
2章 監視のデザインパターン
4つのデザインパターン
- 組み合わせ可能な監視
- 専門化されたツールを複数使い、それらを疎に結合させて、監視「プラットフォーム」を作ること
- 組み合わせ可能な監視の利点として、1つのツールややり方に長期間にわたってコミットする必要がない
- あるツールがやり方に合わなくなってきた時、監視プラットフォーム全体を置き換えるのではなく、そのツールだけを削除して他のもので置き換えればよい
- 監視サービスのコンポーネントは、「データ収集」「データストレージ」「可視化」「分析とレポート」「アラート」の5つ
- データ収集
- データ収集方法はプッシュ型とプル型がある。SNMPやNagiosはプル型の代表例だが、プル型は中央システムがすべてのクライアントを把握してスケジュールし、応答をパースしなくてはならないので、スケールしにくい
- データの集め方は、メトリクスとログの2種類。ログが少なく、grepやtail程度のツールで人間が読む程度なら非構造化ログのままでもよいが、基本的には構造化ログを送るべき
- データストレージ
- 時系列データベース(TSDB,Time Series Database)の多くでは、一定期間後にデータの「間引き」や「有効期限切れ」が発生する
- 可視化
- 円グラフの主な目的は、ある時点での状態の可視化であり、円グラフには、過程やトレンドといった情報が含まれていないので、あまり変化しない値を表現するのに向いています。監視としては、棒グラフの方がよい可視化の方法である場合が多い
- 価値あるダッシュボードには異なる視点とスコープがあり、素晴らしいダッシュボードは、ある場面で持った疑問に回答をくれる
-
ダッシュボードが最も効果的なのは、そのサービスを最もよく理解している人たちによって作られ、運用されている時
- 例)社内メールサービスであれば、その社内メールサービスの管理者がダッシュボードを作るべき
- 分析とレポート
- SLAはよくあるユースケースの一つ
- 2分間のダウンタイムを計測するには1分間隔でデータを収集する必要があり、1秒間のダウンタイムを計測するには、1秒未満の間隔でデータを収集する必要がある
- 内部の冗長なコンポーネントの可用性を無視して、全体の可用性を計算することがおすすめ
- アラート
-
監視とは、質問を投げかけるためにある
- 監視とはアラートを出すために存在しているのではなく、アラートは結果の1つの形でしかない
-
- データ収集
- ユーザ視点での監視
-
まず監視を追加すべきなのは、ユーザがあなたのアプリケーションとやり取りをするところです。Apacheのノードが何台動いているか、ジョブに対していくつのワーカが使用可能かといったアプリケーションの実装の詳細をユーザは気にしません
-
最も効果的な監視ができる方法の1つが、シンプルにHTTPレスポンスコードを使うことです。その次に、リクエスト時間も有益です。このどちらも何が問題なのかは教えてくれませんが、何かが問題で、それがユーザに影響を与えていることは分かります
-
- 作るのではなく買う
-
現時点で監視の仕組みがなかったり、ひどい監視しかしていないなら、監視についての基礎的な部分に取り組むべきで、ツールを気にするのは最低限にしましょう
- 常勤メンバーの平均コスト:年$150,000(米国基準)
-
3人のエンジニアが監視プラットフォームを作るのに1ヶ月かけるということは、3人のエンジニアが会社に直接の売り上げをもたらすことを1ヶ月やるということ
- 多くの会社ではSaaSの監視ソリューションを使うのに年$6,000から年$9,000をかけている
- SaaSを使わない合理的な理由
- SaaS監視サービスでは間違いなく足りない場合
- セキュリティやコンプライアンス上の理由
-
監視にSaaSを非難する人のおおくは、意識的か無意識か偏った考えがあり、技術的あるいは経済的な理由を元にしているわけではありません
-
- 継続的改善
-
世界レベルの仕組みは1週間でできるものではなく、数ヶ月あるいは数年間にわたる継続した注意深さと改善から生まれるもの
-
3章 アラート、オンコール、インシデント管理
アラート
- アラートは、監視の目的を達成するための1つの方法でしかない
- アラートに関する2種類の意味
- 誰かを叩き起こすためのアラート
- 参考情報としてのアラート
- よいアラートの仕組みを作る6つの方法
- アラートにメールを使うのをやめよう
-
メールでアラートを送るのは、受け取る人がうるさくて最もうんざりしてしまう方法
- アラートの使い道は、以下の3つ
- すぐに応答かアクションが必要なアラート(SMS,PagerDuty)
- 注意が必要だがすぐにアクションは必要ないアラート(Slack)
- 履歴や診断のために保存しておくアラート(ログファイル)
-
アラートのログを保持しておいて、後でレポートを送れるようにしておくのは重要です
-
- 手順書(runbook)を書こう
- 手順書は、アラートがきた時にすばやく自分の進むべき方向性を示す方法
- よい手順書は以下のような質問に答えるように書かれたもの
- これは何のサービスで、何をするものか
- 誰が責任者か
- どんな依存性を持っているか
- インフラの構成はどのようなものか
- どんなメトリクスやログを送っていて、それらはどういう意味なのか
- どんなアラートが設定されていて、どの理由は何なのか
- 手順書は、何らかの問題を解決するのに、人間の判断と診断が必要な時のためのもの。コピペできるようなものであれば自動化すべき
- 固定の閾値をきめることだけが方法ではない
- 変化量あるいはグラフの傾きを使うことで、ディスク使用量のアラートの問題をうまく扱える
- アラートを削除し、・チューニングしよう
- アラートを減らす方法
- すべてのアラートは誰かがアクションする必要がある状態か
- 1ヶ月のアラートの履歴を見る。どんなアラートでどんなアクションを取り、各アラートの影響はどうだったか
- どんな自動化の仕組みが作れるか
- アラートを減らす方法
- メンテナンス期間を使おう
- メンテナンス作業中でアラートを送るのは単なる気をそらす邪魔者で、あなたが作業していることを知らないチームメイトがそのアラートを受け取るならなおさらである
- まずは自動復旧を試そう
-
自動復旧によって問題が解決できないなら、アラートを送ればよい
-
- アラートにメールを使うのをやめよう
オンコール
- オンコールとは、何か問題がおきたという呼び出しに答えられるようにしている担当のこと
- アラートをチューニングする方法
- オンコール担当の役割の一つとして、前日に送られたすべてのアラートの一覧を作り、各アラートはどのように改善できるか、アラートを削除してしまえないかを、自問自答する
- 場当たり的対応をやめる2つの習慣
- オンコールシフト中、場当たり的対応をしていない時間は、システムの回復力や安定性に対して取り組むのをオンコール担当の役割にする
- 前週のオンコールの際に収集した情報を元に、次の週のスプリント計画やチーム会議の際にシステムの回復性や安定性について取り上げる計画を立てる
- オンコール担当が4人であれば、各人が1習慣ずつ担当し、その他の3人は3週間担当を外れる仕組みがよい
- カレンダーの週に合わせるのではなく、出勤日にオンコールのローテーションを始めることが重要です
- 会社が大きくなれば、Fllow-the-Sun(太陽を追いかける)ローテーションも効果的
- バックアップのオンコール担当は多くの場合不要だが、エスカレーションパスが必要なのは間違いない
- オンコール担当がアラートに応答しなかったことが1度きりなら、許容すべき。複数回なら別の問題として捉える
- オンコールに対する補償として、オンコールシフトの直後に有給を取得させる、手当を支払う
インシデント管理
-
インシデント管理とは、発生した問題を扱う正式な手順のこと
- 9個のITILプロセスを簡易版として5つのプロセスにまとめたもの
- インシデントの認識(監視が問題を認識)
- インシデントの記録(インシデントに対して監視の仕組みが自動でチケットを作成)
- インシデントの診断、分類、解決、クローズ(オンコール担当がトラブルシュートし、問題を修正し、チケットにコメントや情報を添えて解決済みとする)
- 必要に応じて問題発生中にコミュニケーションを取る
- インシデント解決後、回復力を高めるための改善策を考える
- インシデント対応時の役割(それぞれの役割は1つで、2つ以上の兼務は避けるべき)
- 現場指揮官(IC、incident commander):決断する人
- スクライブ(scribe):記録する人
- コミュニケーション調整役(communication liaison):社内外問わず利害関係者に最新状況のコミュニケーションをとる
- SME(subject matter expert):実際にインシデント対応する人
- インシデント管理の各役割は、通常時のチームの役割と一緒である必要はない
- チームのマネージャーは、ICよりもコミュニケーション調整役にし、エンジニアをICにすることがおすすめ
- PagerDutyのインシデント対応ページ( https://response.pagerduty.com/ )がおすすめ
振り返り(postmortem)
-
インシデント発生後の対応が誰かを非難するものになるなら、内部に潜む本当の問題を改善することは絶対にできません
4章 統計入門
- mean(一般的にはaverage)は、集合内の個数の値を確認することなく、その集合がどのようなものかを表すのに便利な値
- 平均を計算するプロセスの副産物として、グラフの平準化があげられる
- 周期性の高い負荷に対しては、将来どのようにんあるかが推測できる
- パーセンタイルの計算の性質上、ある程度のデータを捨ててしまうことになるので、1日ごとのデータを元に7日の平均を計算しても、1週間のデータを得ることはできない
- 標準偏差は、正規分布しているデータセットに対してしか、期待するような結果は出ない
-
みなさんがこの先、扱うであろうデータのほとんどは、標準偏差が適用できるモデルに当てはまりません
-
5章 ビジネスを監視する
- KPIは、全体としてビジネスがよい状態であるために会社が重要だと認識している計画を、どのように実行しているかを測るためのメトリクス
- 経営者や創業者の視点からの関心
- 顧客はアプリケーションあるいはサービスを使えているか
- 儲かっているか
- 成長しているか、縮小しているか、停滞しているか
- どのくらい利益が出ているか。収益性は改善しているか、悪化しているか、停滞しているか
- 顧客は喜んでいるか
- 事業責任者がよく使うメトリクス
- 月次経常収益(mmonthly recurring revenue)
- 顧客あたりの収益(revenue per customer)
- 課金顧客の数(number of paying customers)
- ネットプロモータースコア(net promoter score、NPS)
- 顧客生涯価値(customer lifetime value、LTV)
- 顧客あたりのコスト(cost per customer)
-
SaaSアプリケーションを提供しているなら、この指標から顧客あたりどのくらいインフラコストがかかっているかを知るとよいでしょう
-
- 顧客獲得単価(customer acquisition cost、CAC)
- 顧客の解約数(customer churn)
- アクティブユーザー数(active users)
- バーンレート(burn rate)
-
会社全体でどのくらいお金を使っているかの指標。この数字は賃金からオフィスの賃貸まですべてを含みます
-
- ランレート(run rate)
-
現在の支出レベルを続けた時に資金がなくなるまでの期間
-
- TAM(total addressable market)
-
ある特定のマーケットがどのくらいの大きさなのかの指標
-
- 粗利(gross profit margin)
- 技術指標に結びつけたビジネスKPI(Redditの例。p.71 表5-1)
ビジネスKPI 技術指標 現在サイトに滞在しているユーザ 現在サイトに滞在しているユーザ ユーザのログイン ユーザのログイン失敗、ログインのレイテンシ コメント投稿 コメント投稿失敗、投稿のレイテンシ スレッド作成 スレッド作成失敗、作成のレイテンシ 投票 投票失敗、投票のレイテンシ プライベートメッセージの送信 プライベートメッセージ送信失敗、送信のレイテンシ Gold購入 購入失敗、購入のレイテンシ 広告購入 購入失敗、購入のレイテンシ -
満足するまで監視を追加し、改善を続けるために、アプリケーションやインフラを変更する
- プロダクトマネージャーに対して、よく使う質問
- 「私が会社に入りたてだとして、アプリケーションが動いていることをどうやって知ったらよいでしょうか?何をチェックしていますか?どう動いていたらよいのでしょうか?」
- 「アプリケーションのKPIは何ですか?なぜそのKPIを使っているのですか?そのKPIはどんなことを教えてくれますか?」
-
ビジネスはそれぞれ違うので、誰もが追跡すべきメトリクスというのはありません
6章 フロントエンド監視
- SPAが広く使われるようになって、HTTPのエラーが起きていないのにJavaScriptのエラーが発生するようなケースも珍しくなくなった
-
フロントエンドのパフォーマンス監視のゴールは、動き続けることではなく、素早くロードされること
- Aberdeen Researchの2010年の研究。ページロード時間が1秒遅くなると、平均でページビューが11%、コンバージョンが7%、顧客満足度が16%下がる
- Aberdeenによると、最適なページロード時間は2秒以下で、5.1秒を超えるとビジネスに影響が出始める
- 最近の例ではPinterest。2017年3月の調査で、体感の待ち時間を40%短縮したことでSEOトラフィックが15%増え、新規登録も15%増えた
- Q.ページロード時間はどのぐらいであるべきか? A.4秒以下
- フロントエンド監視には、GAのようなリアルユーザ監視(real user monitoring, RUM)とWebpage.orgのようなツールによるシンセティック監視(synthetic monitoring)の2つのアプローチがある
-
ブラウザがパースしたDOMと、ブラウザが最終的に表示したページは一致しません
-
HTML5では
<script>タグで、スクリプトのロード時に処理をブロックしないようDOMに伝えるasync属性がサポートされています -
ブラウザは、W3Cによって推奨されているNavigation Timing APIという仕様に基づいたAPIを通じて、ページパフォーマンスのメトリクスを公開しています
- 常に有益なメトリクス
- navigationStart:ブラウザによってページリクエストが開始されたタイミング
- domLoading:DOMがコンパイルされロードが始まったタイミング
- domInteractive:ページが使用可能になったと考えられるタイミング。ただし、ページのロードが終わっているとは限らない
- domContentLoaded:すべてのスクリプトが実行されたタイミング
- domComplete:ページがすべてのロードを終えたタイミング
- 例外やログメッセージを収集し、それをホステッドサービスに送るというのを扱ってくれるプロダクトは、「exception tracking saas」で検索すると出てくる
- 例としては、Sentry, Bugsnagなど
- WebpageTestのAPIを、自動テスト環境で使えるようにすると、新機能のパフォーマンスへの影響をチームが考慮し、苦労して得たパフォーマンス改善の効果を失ってしまわないようにできる
7章 アプリケーション監視
- データベースクエリの実行にかかった時間、外部ベンダーのAPIが応答するのにかかった時間、あるいは、1日に発生したログインの数を計測してみることから始める
- StatsDの組み込み例が中心に掲載されている
-
本当に役立つのは、アプリケーションやインフラのメトリクスと一緒に利用するメタ情報(デプロイがいつ始まったか、いつ終わったか、どのビルドがデプロイされたか、誰がデプロイを実行したかなど)なのです
- Etsyの「Measure Anything,Measure Everything」で、監視を改善する多くの新しいアイディアやツールが生まれた
- デプロイが何らかの問題を引き起こしたという証拠のグラフ
- healthエンドポイントパターン
- カナリヤエンドポイントやステータスエンドポイントという名前でも知られている
- 利点
- ロードバランサーやサービスディスカバリーツールによるヘルスチェックにも使用できる
- デバッグにも使える
- アプリケーションが自分自身の健全性を把握できるようになる
- DBとredisのチェック例
from django.db import connection as sql_connection
from django.http import JsonResponse
import redis
def check_sql():
try: # SQLデータベースに接続し、1行をselect
with sql_connection.cursor() as cursor:
cursor.execute('SELECT 1 FROM table_name')
cursor.fetchone()
return {'okay': True}
except Exception as e:
return {'okay': False, 'error': e}
def check_redis():
try: # Redisデータベースに接続し、キー1つを取得
redis_connection = redis.StrictRedis()
result = redis_connection.get('test-key') # そのキーの値を既知の値と比較
if result == 'some-value':
return {'okay': True}
else:
return {'okay': False, 'error': 'Test value not found'}
except Exception as e:
return {'okay': False, 'error': e}
def health():
if all(check_sql().get('okay'), check_redis.get('okay')):
return JsonResponse({'status': 200},status=200)
else:
return JsonResponse(
{
'mysql_okay': check_sql().get('okay'),
'mysql_error': check_sql().get('error',None),
'redis_okay': check_redis().get('okay'),
'redis_error': check_redis().get('error',None),
},
status=503
)
-
サービスが外部APIに強く依存しているなら、これをチェックしない理由はありません
- セキュリティ上の懸念があるのであれば、特定のソースアドレスだけがこのエンドポイントにアクセスできるようにし、それ以外からのアクセスをリダイレクトすればよい
- 1行のログエントリは、1つのメトリクスよりはずっと多くのメタデータを保持できる
{
"app_name": "foo",
"login_latency_ms": 5,
"username": "mjulian",
"success": false,
"error": "Incorrect password"
}
- ログは何でもかんでも全部取ると、様々な問題が生じる
-
トラブルシューティングあるいは単なる仕組みの説明時に、あったらとても便利な情報とはなんでしょうか。その質問から始めましょう
- 1秒以下の監視は、伝統的なポーリングモデルでは難しい
- 分散トレーシングとは、マイクロサービスアーキテクチャに付き物の複雑なサービス間のやり取りを監視するための方法論とツールチェーンのこと
- GoogleのDapper論文で有名になり、ZipkinとしてGoogle外で実装された
-
分散トレーシングは、正しく実装するのは非常に難しく時間がかかる監視の仕組みであり、業界内の一部でだけ役に立つものである
8章 サーバ監視
- OSの標準的なメトリクス
- OSの標準的メトリクスのおすすめの使い方は、全システムで自動的に記録するようにしておきつつ、アラートは設定しないでおくこと
- ログ監視ツールで、OOMKillerの発生時にアラートを送る仕組みを作るのがおすすめ
- ユーザに何も影響がないなら、ロードが高いのは実際問題ではありません
- SSL証明書
- SNMP
- SNMPはサーバ監視に使うものではない
- Webサーバ
- コネクション数とはリクエスト数ではないので、コネクション数よりはリクエスト数に注目すべき
- データベース・サーバ
- データベースパフォーマンスの監視とチューニング書籍
- 実践ハイパフォーマンスMySQL
- Database Reliablity Engineering
- データベースパフォーマンスの監視とチューニング書籍
- ロードバランサー
- ロードバランサーは、フロントエンドとバックエンドの両方のメトリクスを取得しておく
- メッセージキュー
- メッセージキューのキューの長さ(queue length)と消費率(consumption rate)を監視する
- キャッシュ
- キャッシュの主なメトリクスは、キャッシュから追い出されたアイテム数(evicted item)とヒット・ミス比率(hit/miss rario)
- DNS
- NTP
- それ以外(DHCP,SMTP)
- スケジュールジョブの監視
- データが存在しないことを検知するデッドマン装置(dead man’s switch)を作る
- ロギング
- 3つの問題。「収集」「保存」「分析」
- ログの解析は、Splunk, ELKスタック,あるいはそれ以外のSaaSツールなどを使えばよい
9章 ネットワーク監視
-
ネットワークがスリーナインの可用性(99.9%)を維持する能力しかないなら、アプリケーションがフォーナイン(99.99%)を実現することはできない
-
SNMPは、デバイスを監視し管理することを目的に1988年にRFC1067で提案されたプロトコル
- SNMPの通信には、エージェントとマネージャという2つの考え方がある
- 2002年に発表されたバージョン3が、SNMPの最新バージョン
- ネットワークパフォーマンスの5つの要素
- 帯域幅(bandwidth)
- ある接続から一度に送れる理論上の最大情報量
- 秒間ビット(bit per second,bps)で表されることが多い
- スループット(throughput)
- ネットワークリンクの実際のパフォーマンス
- MTUが1,500バイトのEthernetリンクでは、カプセル化のオーバーヘッドで、TCPストリームの最大スループットは帯域幅の95%に制限される
- レイテンシ(latency)
- パケットがネットワークリンクをつうじてやり取りされるのにかかる時間
- エラー(errors)
- 送受信エラー、ドロップ、CRCエラー、オーバーラン、キャリアエラー、リセット、コリジョン
- 電気的干渉、送受信機やケーブルの欠陥は、CRCエラーとキャリアエラーから監視できる
- ジッタ(jitter)
- あるメトリックの、通常の測定値からの狂いのこと。レイテンシが揺れ動くなら、ジッタが大きい例である
- 帯域幅(bandwidth)
- ネットワークの例え話(片側4車線の高速道路)
- 音声と映像のパフォーマンスは、レイテンシ、ジッタ、パケットロスの3つの計測項目がすべて
- ダイナミックルーティングプロトコルは、自己回復的な動作をするよう作られているので、いつ誰かにアラートをおくるべきかの判断が難しい
- Ciscoの7つのフロー監視定義
- 入力インタフェイス(SNMPのifIndex)
- 送信元IPアドレス
- 宛先IPアドレス
- L3プロトコル
- UDPまたはTCPの送信元ポート
- UDPまたはTCPの宛先ポート
- IP ToS(Type of service)
- フロー監視の実装例
- NetFlow
- sFlow
- J-Flow
- IPFIX
- キャパシティプランニングの2つの方法
- ビジネス上の必要性から逆算する
- 使用状況に応じて未来を予測する
10章 セキュリティ監視
-
セキュリティとは、脅威とリスクを見積もり、不正サクセス時に決断を下すこと
- コンプライアンス規制の例
- HIPAA(ヘルスケアデータの保護)
- SOX法(上場企業の会計情報の保護)
- PCI-DSS(クレジットカードデータの保護)
- SOC2(会計以外の統制情報の保護)
- 各規制の文言例
- 1.3.5 ネットワーク内へ「確立された」接続のみを許可する(PCI-DSS v3.2)
- 5.2 すべてのウィルス対策メカニズムがいかのように維持されていることを確実にする(PCI-DSS v3.2)
- 最新の状態である
- 定期的にスキャンを行う
- PCI DSS要件10.7に従って監査ログを生成・保持する
- auditdによる、ユーザアクションの監視方法紹介
- すべてのsuduの実行、コマンドの実行、誰が実行したか
- ファイルアクセスや特定ファイルの変更、その時刻、誰によって変更されたか
- ユーザ認証の試行と失敗
- ログの取り込みにrsyslogを使わない理由
-
auditdは、動作するにあたってsyslogサブシステムには依存していないので、rsyslogが無効化されていてもauditdは監査イベントを記録し、リモートサーバにそれを転送し続けられます
-
- ホスト型侵入検知システム(HIDS)
- ルートキットの検知としてrkhunterがcronjobでの定期実行のやり方も含めて紹介されている
- ネットワーク型侵入検知システム(NIDS)
- NIDSはネットワークタップ(ネットワークの中に配置するハードウェアで、そこを通過するすべてのトラフィックを傍受し、そのコピーを他のシステムに送るもの)をネットワーク内に配置して生のトラフィックを確認することで動作する
-
ネットワークタップをデプロイしたら、分析のためにトラフィックをセキュリティ情報イベント管理(security information and event maangement, SIEM)システムに送る必要があります
- SIEMのオープンソースの例としては、Bro, Snort
11章 監視アセスメントの実行
- 架空のフレンチフライレビューサイトTaterを例に、監視アセスメントの実行方法を紹介
- ビジネスメトリクス例
- レストランのレビュー数
- アクティブなレストラン(オーナーがログインしている)の数
- ユーザ数
- アクティブユーザ数
- 検索実行数
- レビュー投稿数
- 広告購入数
- 上記各項目の変化の方向と変化率
- ユーザからのNPS
- レストランからのNPS
- 仮想アーキテクチャのメトリクス例
- ページロード時間
- ユーザログイン:成功数、失敗数、実行時間、1日のアクティブユーザ数、1週間のアクティブユーザ数
- 検索:検索実行数、レイテンシ
- レビュー:レビュー投稿数、レイテンシ
- (アプリケーションから見た)PostgreSQL:クエリレイテンシ
- (データベースサーバから見た)PostgreSQL:秒間トランザクション数
- (Redisサーバ絡みた)Redis:秒間トランザクション数、ヒット・ミス比率、キャッシュから追い出されたアイテム数
- CDN:ヒット・ミス比率、オリジンに対するレイテンシ
- HAProxy:秒間リクエスト数、利用可能・不能なバックエンドの数、フロントエンドとバックエンドでのHTTPレスポンスコード
- Apache:秒間リクエスト数、HTTPレスポンスコード
- 標準的なOSメトリクス:CPU使用率、メモリ使用率、ネットワークスループット、ディスクIOPSと空き容量
- 仮想アーキテクチャのログ例
- ユーザログイン:ユーザID、コンテキスト(成功、失敗、失敗の理由)
- Django:例外、トレースバック
- 使用しているすべてのサーバサイドデーモンのサービスログ:Apache,PostgreSQL,Redis,HAProxy
- セキュリティ監視例
- SSHログインの試行と失敗
- sylogのログ
- auditdのログ
- アラート例
- ページロード時間の増加
- Redis, Apache, HAProxyでのエラー率やレイテンシの増加
- 検索、レビュー投稿、ユーザログインといった、アプリケーションの特定のアクションのエラー率やレイテンシの増加
- PostgreSQLクエリのレイテンシの増加
付録
- 付録A 手順書の例
- 付録B 可用性表
- 付録C 実践監視SaaS
- 監視SaaSの利点
- SaaS監視を使うことで「監視の民主化」が実現しやすくなる
- 新しい機能が追加開発され、それらをバージョンアップ作業などをせずに自動で利用できる
- 監視SaaSは信用できるのか
- 「監視SaaSビジネスそのものに対する信頼性」「事業の継続性」「サービス品質」「悪意はないか」の4点の観点から、監視SaaSを選ぶ際に考慮すべきことを紹介
- 監視SaaSの選定時に考えること
- 課題を見つける
- 機能要件を精査する
- 組み合わせて使う
- 運用をサービスに合わせる
- ハッカビリティ(自分たちでコードを書いて工夫や拡張がしやすいか)を備えているか
- 外部の力を活用できるか
- 監視を育てる
-
監視は1回作って終わりではありません。アプリケーションコードと同様にメンテナンスしていくもの
-
筆者はそれを「監視を育てる」と言っています
-
- 監視パラダイムの変遷
- Observabilityが新しいパラダイム
- これまでの監視に加えて、本書でも触れられているログやイベント、そして分散トレーシングも含まれている
- 機械学習と異常検知
- Observabilityが新しいパラダイム
- 監視SaaSの利点